
 346-200-6097
346-200-6097
The Role of Hashing in Preserving Evidence Authenticity
In digital forensics, one question matters above all others: has the evidence been altered or is it the same as when it was originally collected? Whether you're an attorney preparing for trial, an investigator building a case, or a business owner facing a data breach, you need to know that the digital evidence you're relying on is exactly what it claims to be. This is where hash values become indispensable.
A hash value is essentially a fingerprint for data. It's a unique string of characters generated by a mathematical algorithm that identifies the contents of a file, drive, or any digital data. Even the slightest change to the original data, down to a single bit, produces a completely different hash value. At Black Dog Forensics, we've used hash verification in hundreds of cases ranging from Capital Murder, Human Trafficking, to basic litigation. This article explains what hash values are, how they work, and why they form the foundation of defensible digital evidence.
What is a hash value?
A hash value is a fixed-length string of characters generated by running data through a hash function. Think of it as a mathematical summary of the data. No matter if you're hashing a one-page document or a 2-terabyte hard drive, the resulting hash value will always be the same length for a given algorithm.
Hash values have four fundamental properties that make them invaluable for forensic work:
- Fixed length: Every hash output from a specific algorithm is always the same size. MD5 always produces 32 hexadecimal characters. SHA-256 always produces 64.
- Deterministic: The same input will always produce the same hash value. Run the same file through the same algorithm today or ten years from now, and you'll get identical results.
- Unique: Different data produces different hash values. While under certain circumstances it is mathematically possible for two different files to share a hash (a collision), it's practically impossible with modern algorithms.
- One-way: You cannot reverse-engineer the original data from a hash value. The process only works in one direction.
The avalanche effect illustrates this perfectly. Hash the word "hello" using SHA-256 hashing algorithm and you get: 2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824. Change just one letter to "Hello" (capital H) and the result is completely different: 185f8db32271fe25f561a6fc938b2e264306ec304eda518007d1764826381969. This sensitivity to change is exactly what makes hashing so powerful for detecting tampering.
How hashing works
The hashing process is conceptually straightforward, even if the mathematics behind it are complex. Here's how it works in practice:
First, you provide input data. This could be a single file, a group of files, or an entire disk image. The hash algorithm then processes this data through a series of mathematical operations. These operations mix, compress, and transform the input in ways that ensure even tiny changes produce dramatically different outputs. Finally, the algorithm generates a fixed-length hash value that serves as a unique identifier for that specific data.
The deterministic nature of hashing is what makes it so reliable for forensic work. If you hash a hard drive, create a forensic copy, and then hash that copy, matching values prove the copy is bit-for-bit identical to the original. This isn't an approximation. It's mathematical certainty.
The most commonly used hash algorithms in digital forensics are MD5, SHA-1, and SHA-256. MD5 has been around since 1991 and remains widely used despite known vulnerabilities. SHA-1 produces longer hashes and was once considered more secure, but it too has been compromised in laboratory settings. SHA-256, part of the SHA-2 family, is the current gold standard for security-critical applications.
Why hashing is critical in digital forensics
Hashing serves one primary purpose in digital forensics: proving evidence integrity. When a forensic examiner collects digital evidence, they must demonstrate that what they analyzed is exactly what was originally seized. Hashing makes this possible.
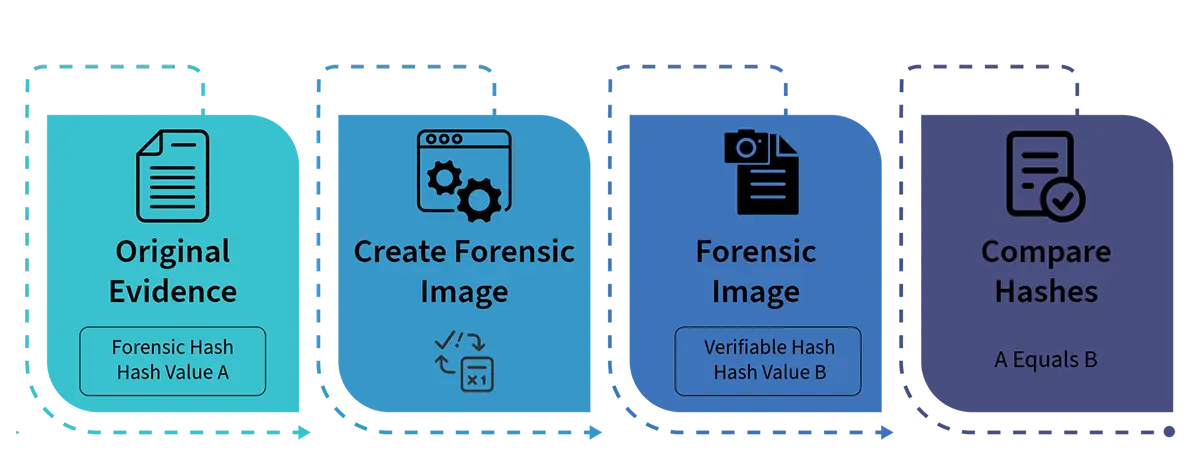
The standard forensic workflow follows four steps:
- Calculate the hash value of the original evidence
- Create a forensic image (a bit-by-bit copy of the original)
- Calculate the hash value of the forensic image
- Verify that the two hash values match
Matching hashes prove the forensic image is identical to the original device. Any discrepancy, no matter how small, indicates that something has changed. This could mean tampering, corruption, or a problem with the imaging process. Either way, the examiner knows immediately that the evidence cannot be trusted.
This verification process is essential for maintaining the authenticity. The real-world applications extend across virtually every type of digital investigation:
- Child exploitation cases: Law enforcement maintains databases of hash values for known illegal content. NCMEC's CyberTipline uses hash values to help identify victims and perpetrators.
- Trade secret theft: Companies can use hash values to prove that files found on a former employee's device are identical to proprietary documents.
- Malware analysis: Security researchers use hashes to identify known malicious files and track their distribution.
- Document authentication: Hash values can verify that contracts, emails, or other documents haven't been altered since they were created.
Common hash algorithms used in digital forensics
Not all hash algorithms are created equal. Understanding the differences is essential for choosing the right tool for your forensic work.
MD5 (Message Digest Algorithm 5)
MD5 was developed in 1991 by Dr. Ronald Rivest at MIT. It produces a 128-bit hash value displayed as 32 hexadecimal characters. For decades, MD5 was the standard hash algorithm for digital forensics and remains widely used today.
MD5's continued popularity stems from its speed and widespread support. Virtually every forensic tool supports MD5, and it calculates quickly even on large data sets. Many legacy systems and established workflows rely on MD5 hashes.
However, MD5 has known vulnerabilities. In 2004, researchers demonstrated that it was possible to create two different files with the same MD5 hash value, a collision. The HashClash project and subsequent research have made generating MD5 collisions achievable with modest computing resources. This doesn't mean MD5 is useless for forensics, but it does mean that MD5 alone may not be sufficient for applications requiring the highest level of cryptographic security.
SHA-256 (Secure Hash Algorithm 256)
SHA-256 is part of the SHA-2 family developed by the National Security Agency and published by NIST in 2001. It produces a 256-bit hash value displayed as 64 hexadecimal characters.
SHA-256 is significantly stronger than MD5. No practical collisions have been demonstrated, and the algorithm is designed to resist the types of attacks that compromised MD5 and SHA-1. For this reason, SHA-256 has become the recommended standard for modern forensic work, particularly for evidence that will be presented in court.
The trade-off is that SHA-256 calculations take longer than MD5, though on modern hardware the difference is rarely significant for most forensic applications.
Using multiple hash algorithms
Many forensic examiners calculate both MD5 and SHA-256 hashes for critical evidence. This defense-in-depth approach provides redundancy. Even if a vulnerability were discovered in one algorithm, the other would remain valid. Courts increasingly expect this level of thoroughness for high-stakes cases.

Hashing tools used by forensic examiners
Professional forensic examiners rely on a variety of tools to calculate and verify hash values. These range from comprehensive forensic platforms to simple command-line utilities.
Commercial forensic platforms include FTK Imager from Exterro (formerly AccessData), EnCase from OpenText, and X-Ways Forensics. These tools automate hash calculation during the imaging process and maintain hash verification as part of their case management workflow. When you create a forensic image using FTK Imager, for example, the software automatically calculates MD5 and SHA-256 hashes and embeds them in the image metadata.
Free and open-source tools provide alternatives for independent verification. HashCalc is a simple Windows utility for calculating hashes of individual files. Linux and macOS systems include command-line tools like md5sum and sha256sum. These utilities allow examiners to verify hashes using tools completely separate from the original imaging software, adding another layer of confidence.
The key principle is independence. Verifying a hash with a different tool than the one that created it reduces the risk of software bugs or manipulation affecting the results.
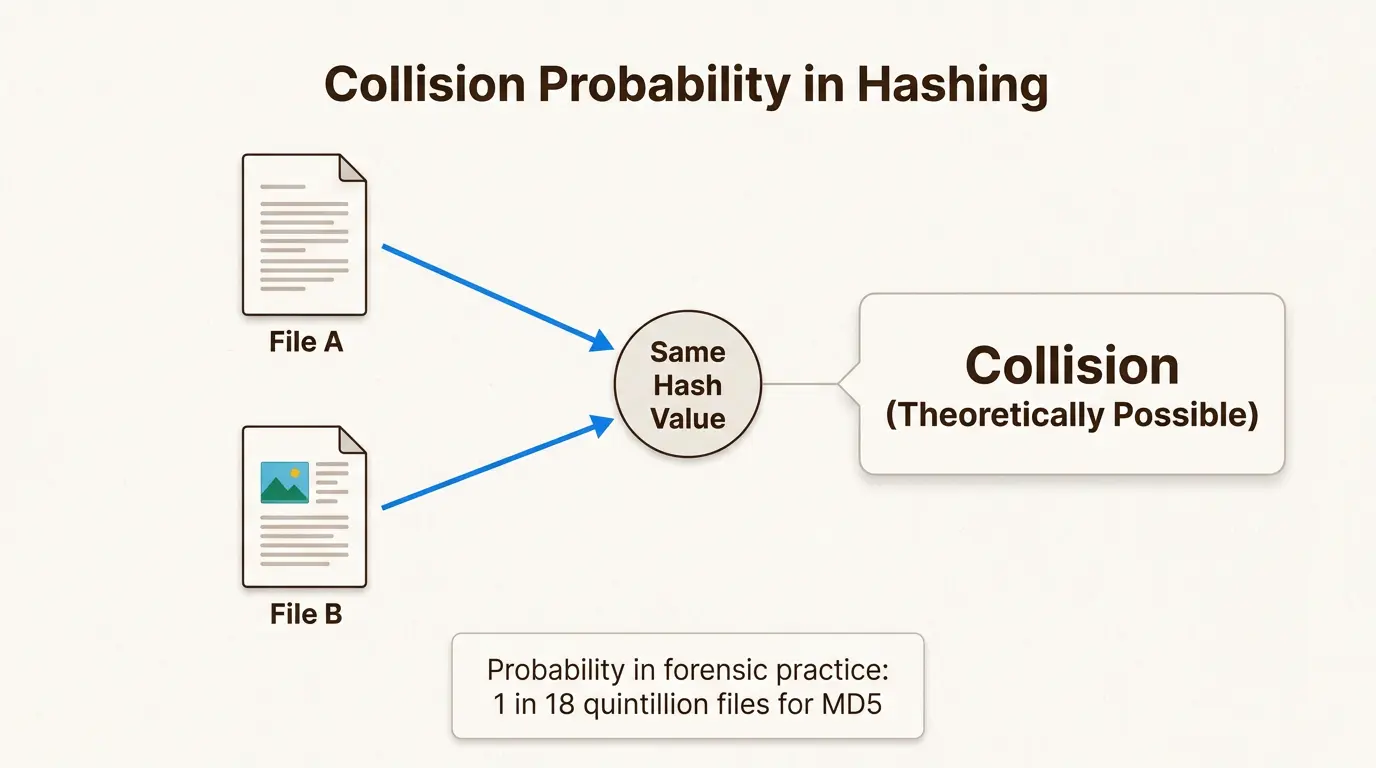
Understanding hash collisions
A hash collision occurs when two different inputs produce the same hash value. This violates the uniqueness property that makes hashing useful, and understanding collisions is essential for evaluating the reliability of hash-based evidence.
Collisions are mathematically possible for any hash algorithm because there are infinite possible inputs but a finite number of possible hash outputs. However, the probability of a random collision is astronomically low for well-designed algorithms. As Holland & Knight noted in their analysis of forensic hashing, the number of files required for a 50% probability of an MD5 collision is approximately 2^64, or about 18 quintillion files. A typical computer case with 10 million files has a collision probability so low it can be effectively dismissed.
The demonstrated MD5 collisions that exist were not accidental. They required deliberate mathematical construction by researchers with significant computing resources. Creating a collision for a specific target file remains computationally infeasible. To date, we are not aware of a known instance of a hash collision in the wild that has not been mathematically constructed.
For forensic verification, this distinction between theoretical possibility and practical reality is crucial. Hash verification in forensic work involves comparing known evidence sources, not random files. An examiner hashes a specific hard drive and compares it to a forensic image of that same drive. The question isn't whether any two random files might collide, but whether someone could have deliberately constructed a different version of this specific evidence that produces the same hash. For MD5, this remains practically impossible. For SHA-256, it's effectively impossible.
Best practices for hash verification in digital investigations
Following established best practices ensures that hash verification will hold up under scrutiny in court:
- When possible, hash original evidence before any analysis begins. This establishes the baseline for all subsequent verification.
- Hash forensic images and verify against the original hash before starting analysis.
- Document all hash values in forensic reports with the algorithm used and the time of calculation.
- Verify hashes prior to any investigation of the data, particularly after any data transfer, including when providing copies to opposing counsel.
- Use multiple hash algorithms when case stakes justify the additional effort.
- Maintain chain of custody documentation that includes hash verification.
When an examiner testifies in court, hash values provide objective, mathematical proof of evidence integrity. They can state with certainty that the evidence they analyzed is identical to what was originally collected, backed by hash values that any expert can independently verify.
Real-world example: hash verification in action
Consider a typical scenario. A forensic examiner is tasked with imaging a hard drive from a laptop involved in a trade secret theft investigation.
The examiner connects the original drive using a hardware write-blocker to prevent any changes. They calculate the hash values:
- Original device MD5: d41d8cd98f00b204e9800998ecf8427e
- Original device SHA-256: e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
The examiner then creates a forensic image using FTK Imager, producing an E01 file. After imaging completes, they calculate hashes of the image:
- Forensic image MD5: d41d8cd98f00b204e9800998ecf8427e
- Forensic image SHA-256: e3b0c44298fc1c149afbf4c8996fb92427ae41e4649b934ca495991b7852b855
The hashes match exactly. The examiner can now testify that the forensic image is a bit-for-bit identical copy of the original evidence. All subsequent analysis is performed on the image, leaving the original drive sealed and preserved.
If the hashes hadn't matched, the examiner would know immediately that something went wrong. Perhaps the imaging process encountered errors, or the original drive has bad sectors that affected the copy. Either way, the discrepancy prevents the examiner from proceeding with confidence.
Ensure digital evidence integrity with professional forensic analysis
Hashing is one of the fundamental scientific principles underlying digital forensic investigations. It transforms the abstract concept of "evidence integrity" into a verifiable, mathematical certainty. Without hash verification, digital evidence would be vulnerable to challenges of tampering and manipulation. With it, forensic findings become defensible in court.
Hash verification ensures:
- Evidence integrity from collection through analysis
- Reproducibility of forensic findings by independent experts
- Trust in the authenticity of digital evidence
- Defensibility of expert testimony under cross-examination
At Black Dog Forensics, we follow rigorous protocols for forensic imaging and hash verification on every case. Our experts have provided testimony in hundreds of cases nationwide and across the world. We understand that our job is to retrieve the truth, following the digital trail with focus and integrity until we uncover what actually happened.
If you're facing a matter involving digital evidence, contact Black Dog Forensics. We provide court-admissible forensic analysis that stands up to the highest standards of legal scrutiny.




